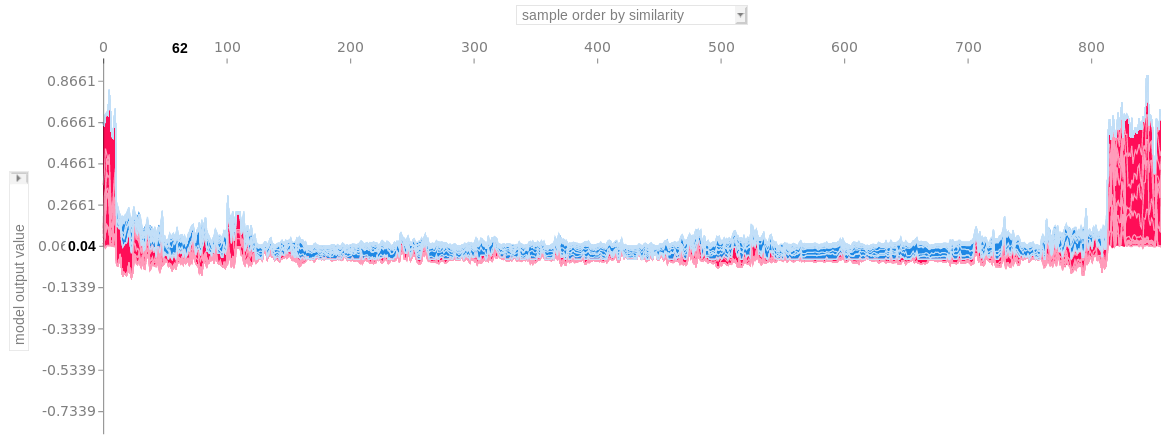
3. Global Model-Agnostic Methods
Resumen del libro de Molnar
2.4 Ejemplo - bicis
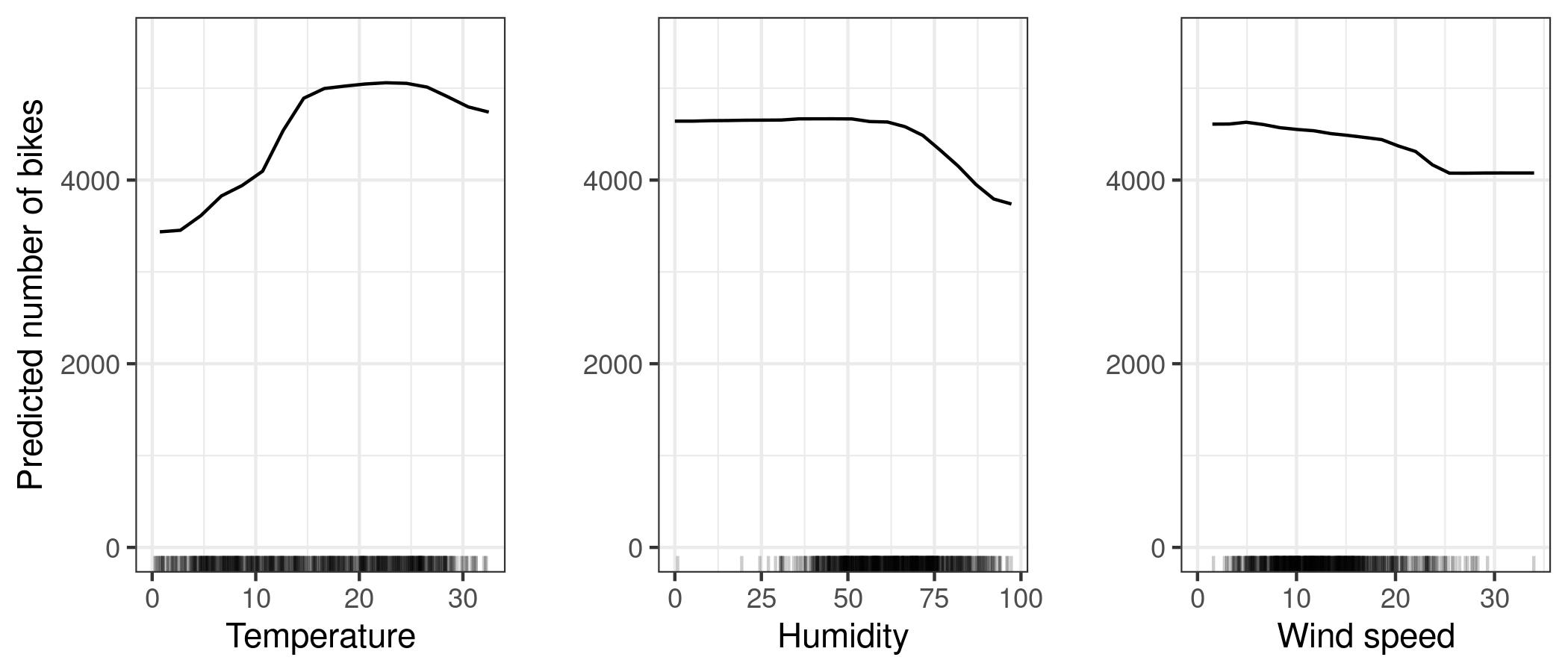
https://christophm.github.io/interpretable-ml-book/images/pdp-bike-1.jpeg
2.5 Ejemplo 2D - cáncer
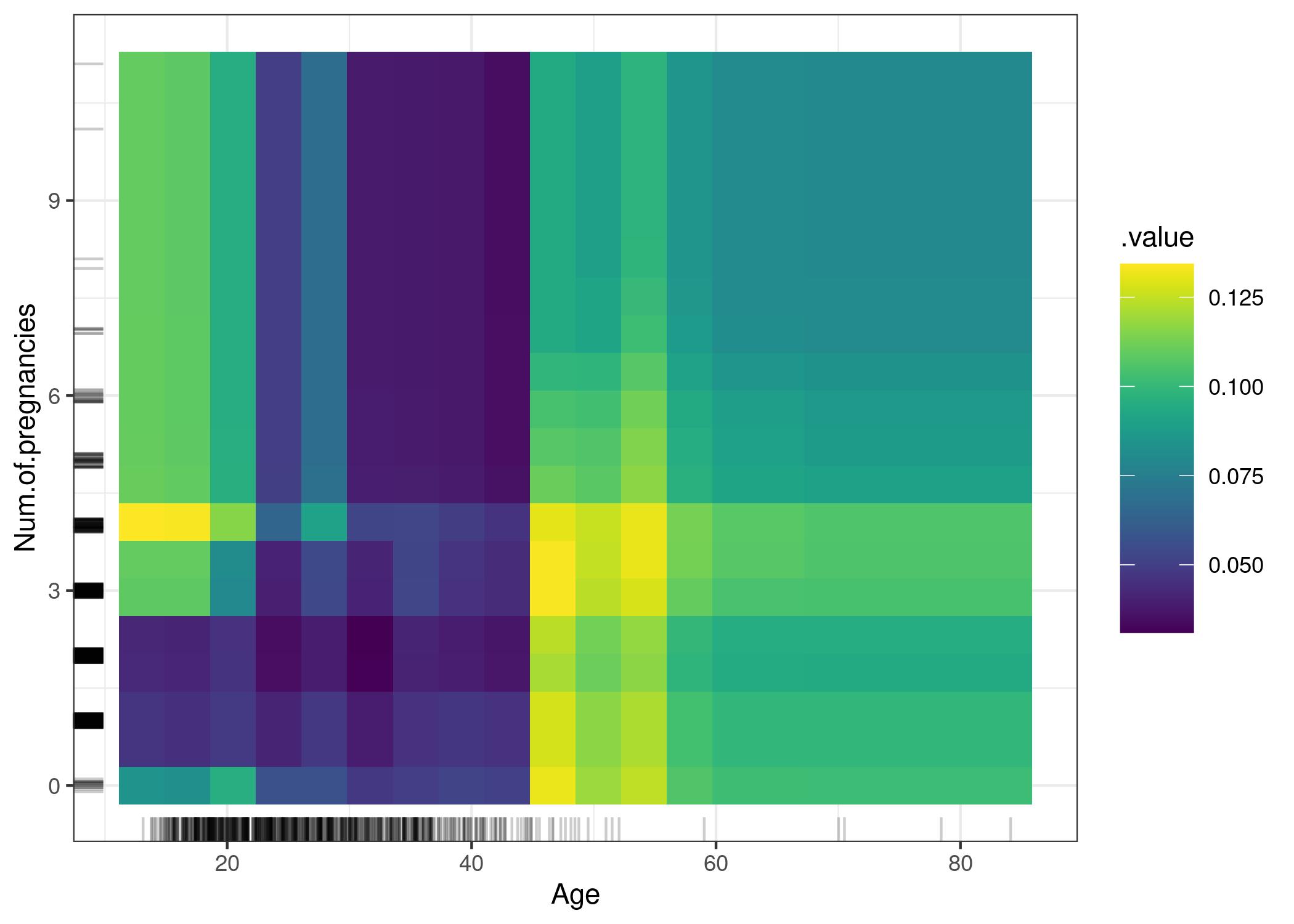
https://christophm.github.io/interpretable-ml-book/images/pdp-cervical-2d-1.jpeg
3.2 Motivación - Solución a datos heterogéneos en PDP
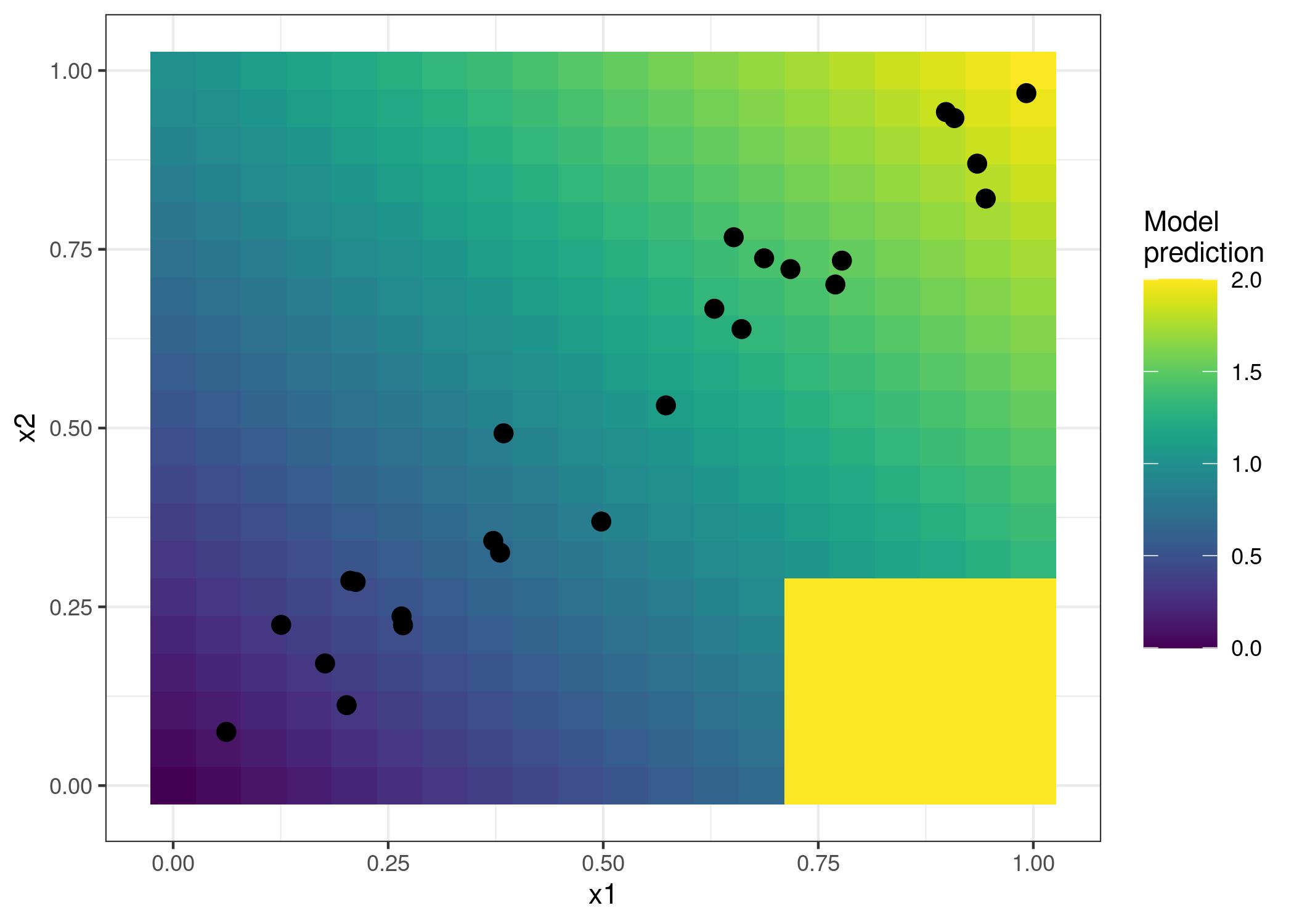
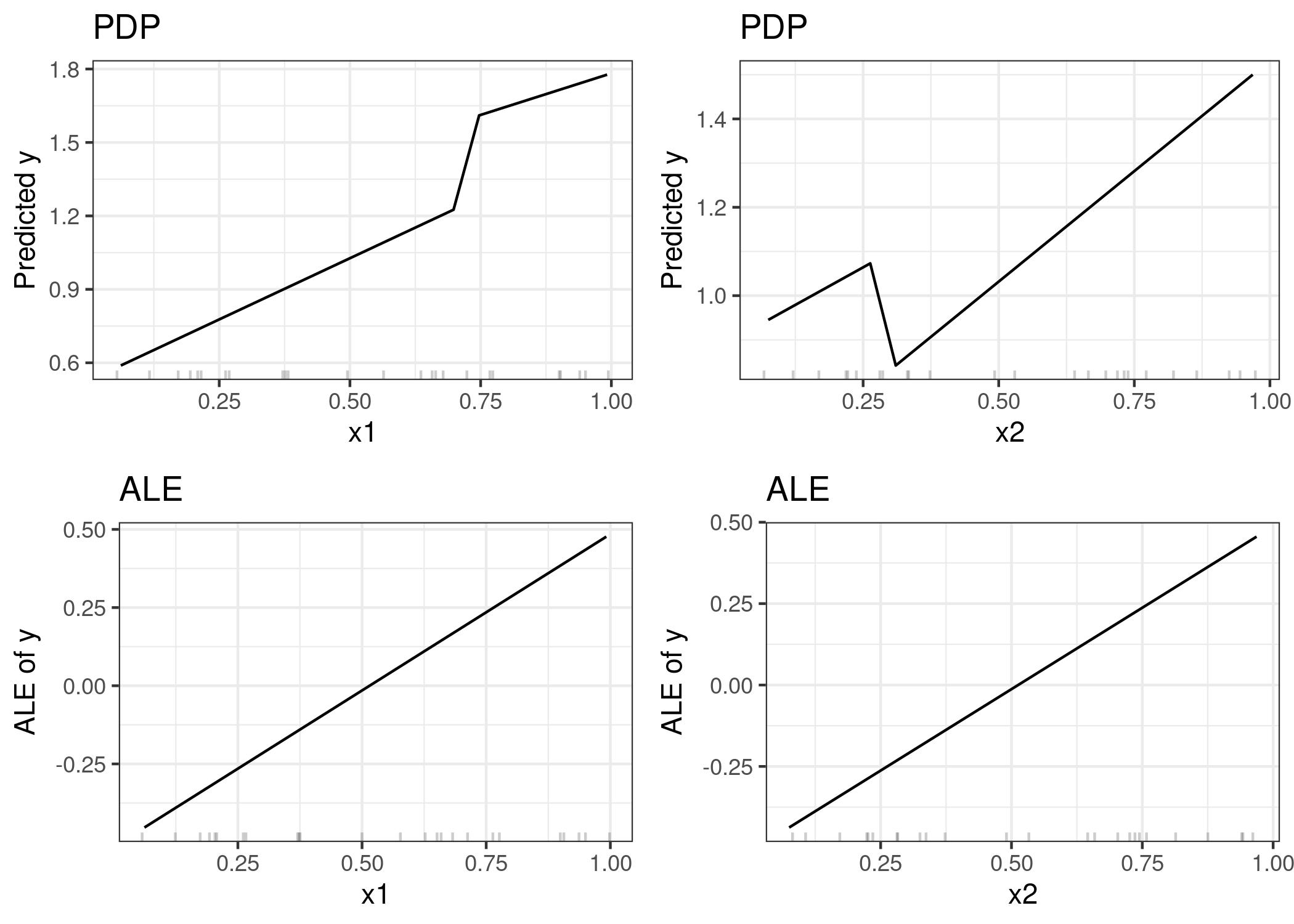
3.4 Ejemplo - bicis
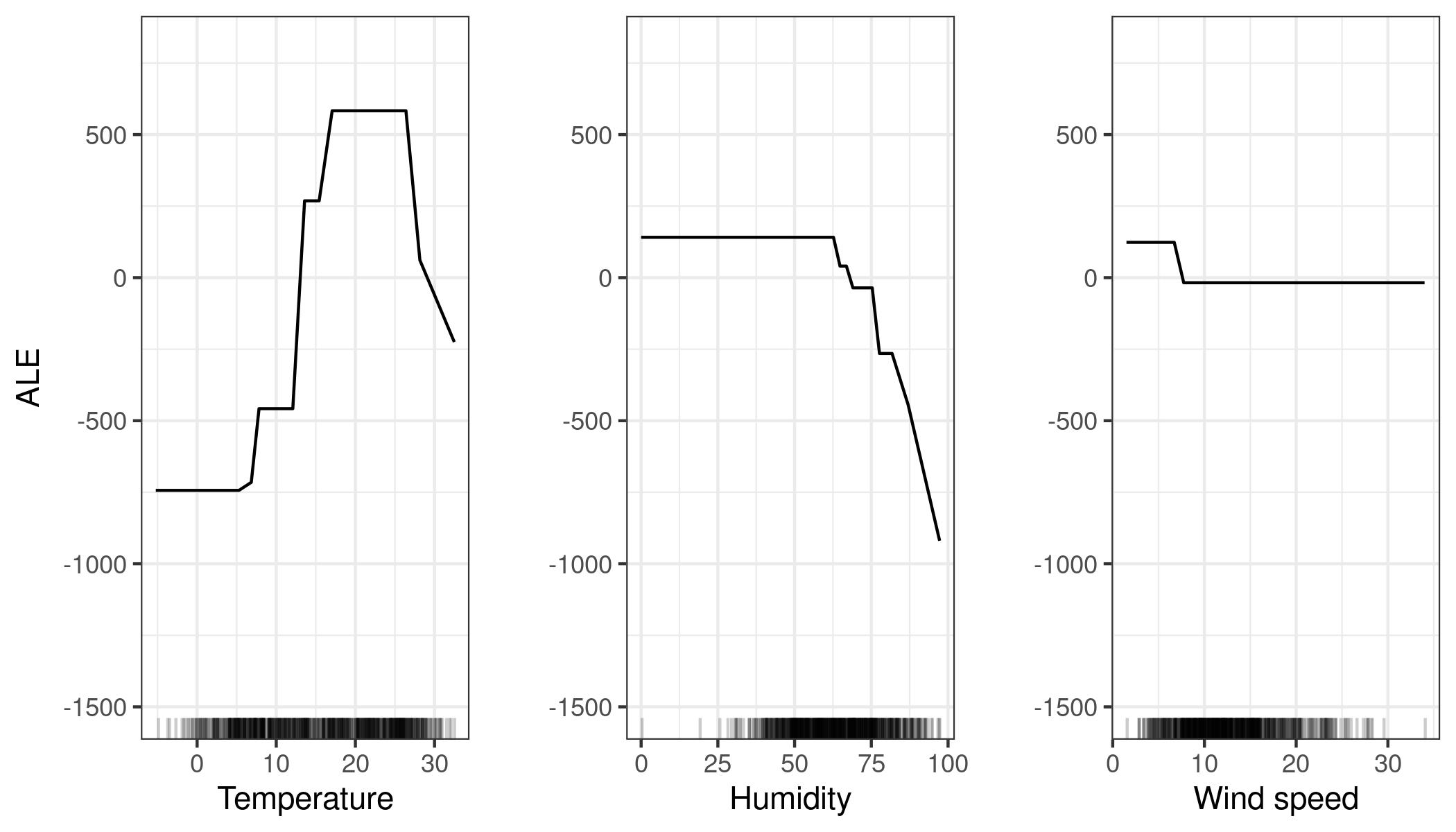
https://christophm.github.io/interpretable-ml-book/images/ale-bike-1.jpeg
3.5 Ejemplo 2D - bicis
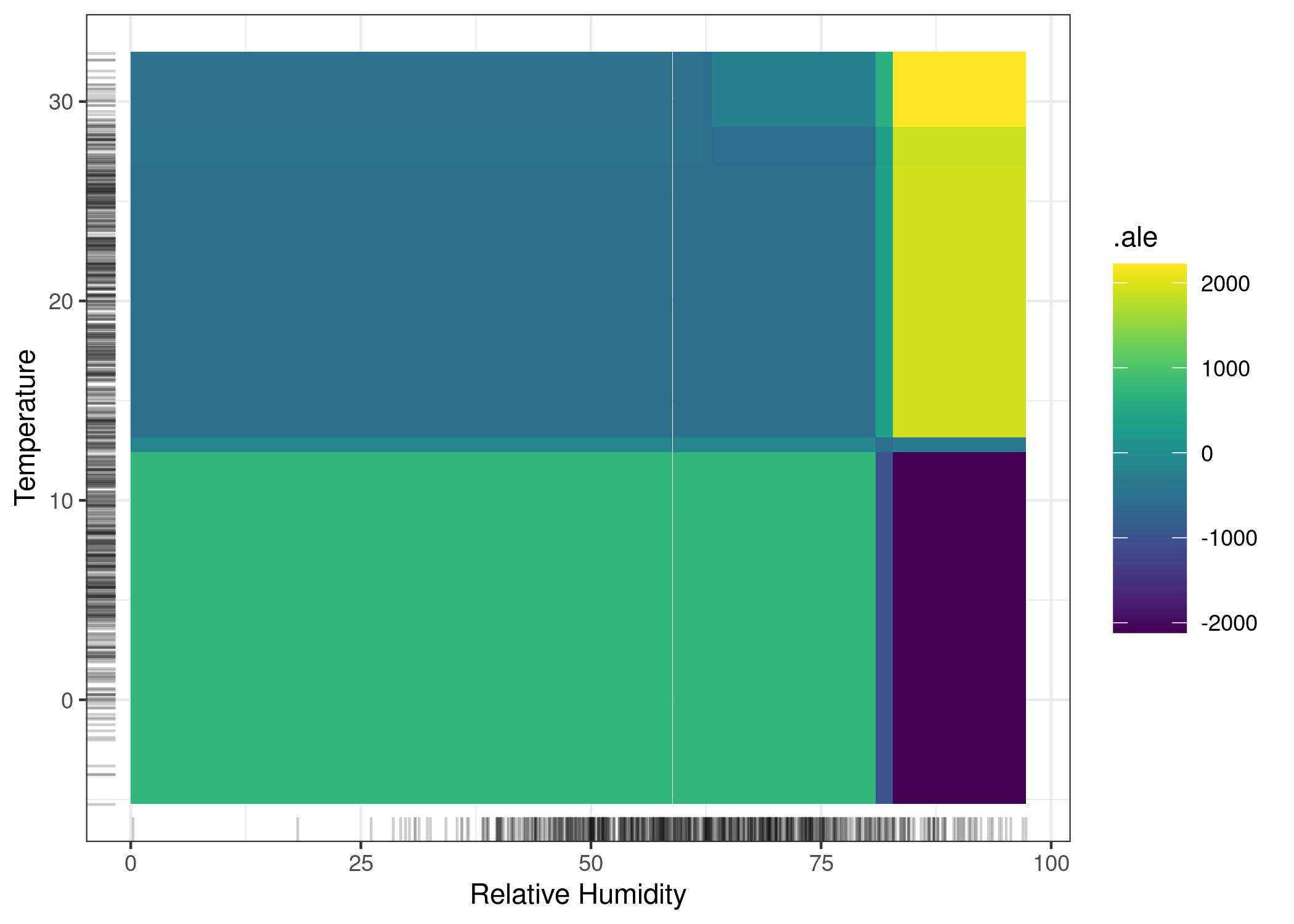
https://christophm.github.io/interpretable-ml-book/images/ale-bike-2d-1.jpeg
La interpretación para 2 atributos puede ser complicada. Un dato alto de ALE no implica que el valor real sea más alto, si no que cuando los 2 atributos concurren en la misma zona el valor es más alto que si estuvieran separados. Pero no quiere decir que el valor sea más alto per se, porque los atributos por separado pueden hacer tender los datos hacia abajo.
4.5 Ejemplo - parejas - cáncer
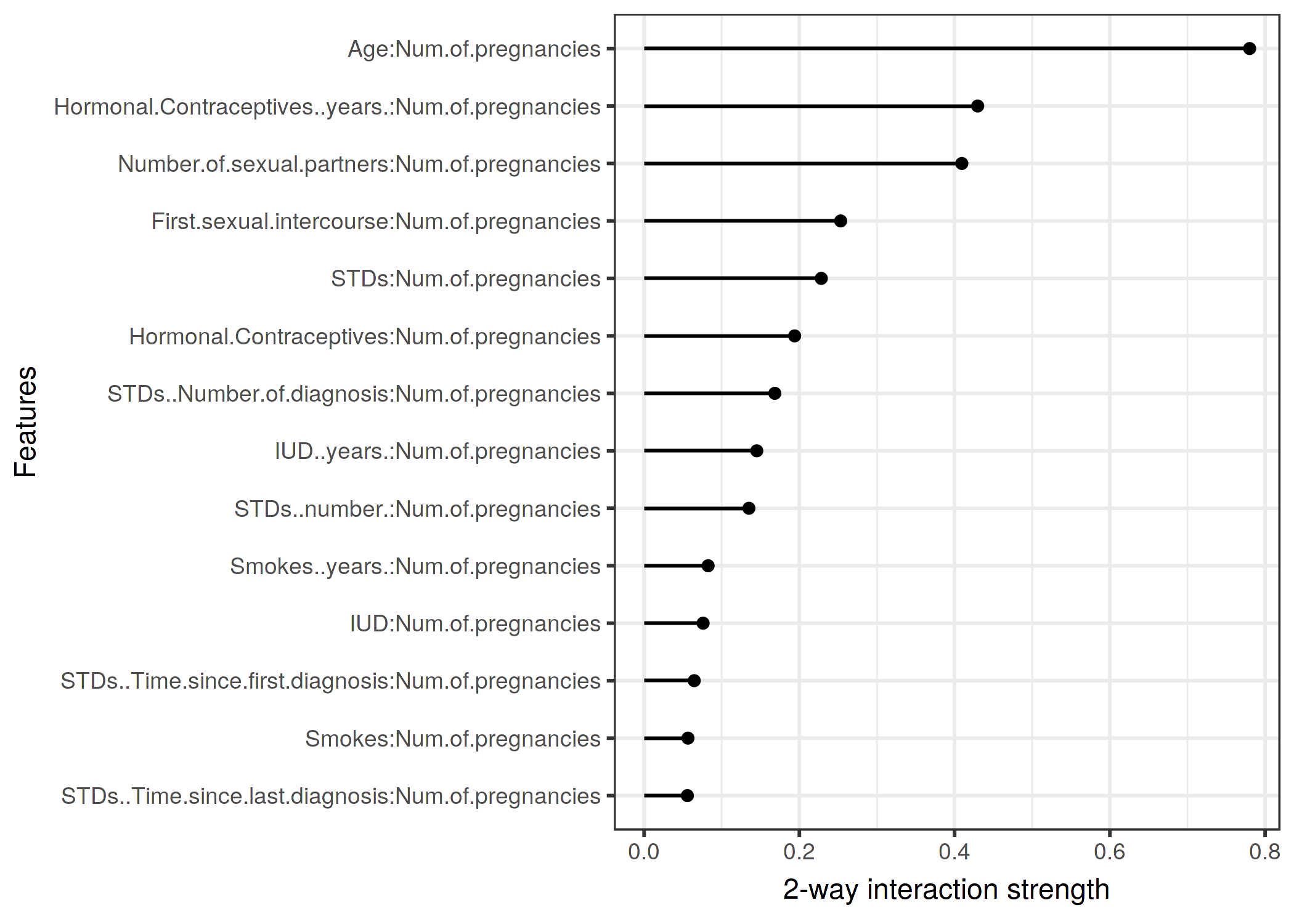
https://christophm.github.io/interpretable-ml-book/images/interaction2-cervical-age-1.png
4.6 Ejemplo - 1 contra todos - cáncer
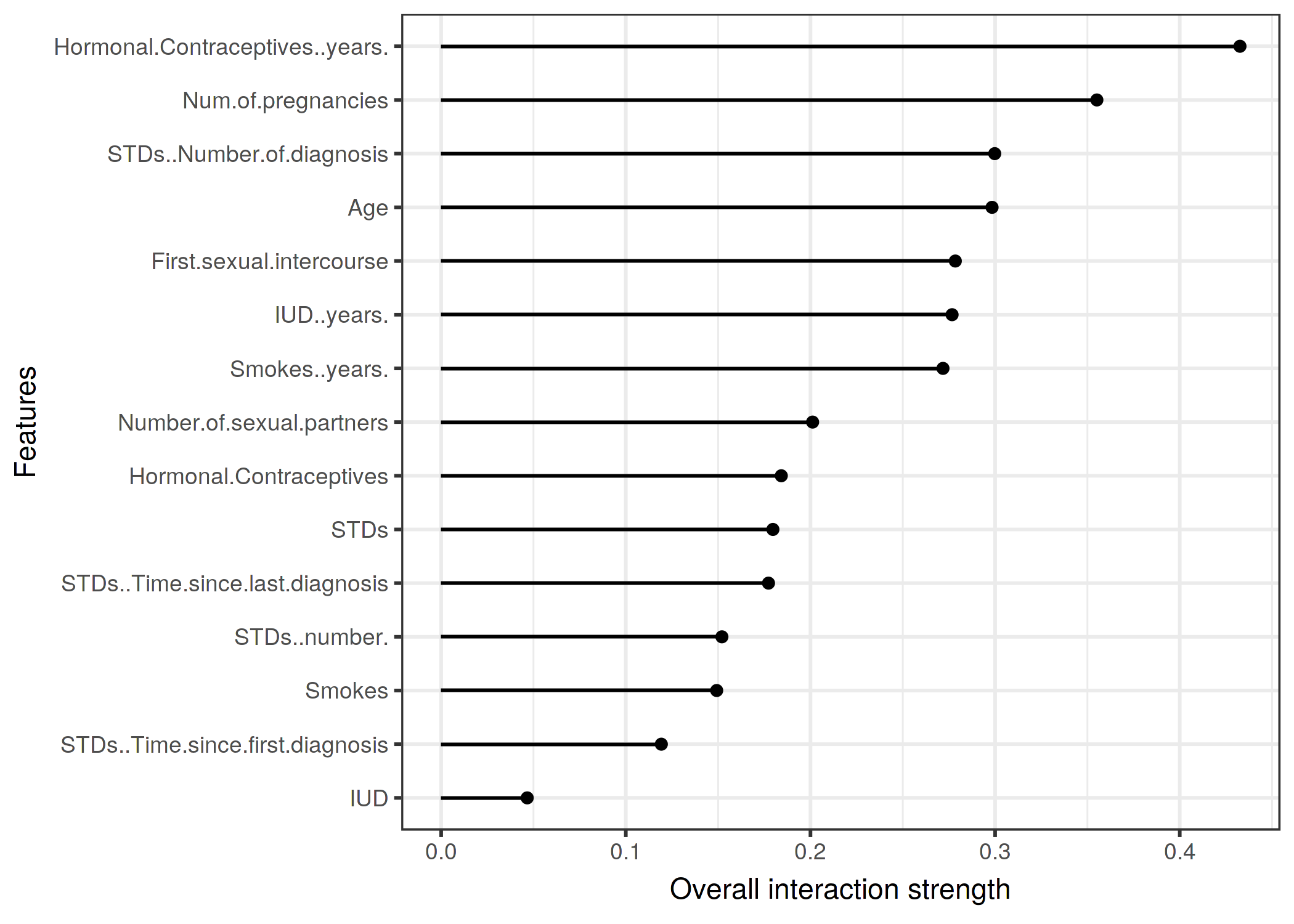
https://christophm.github.io/interpretable-ml-book/images/interaction-cervical-1.png
6.3 Ejemplo - bicis
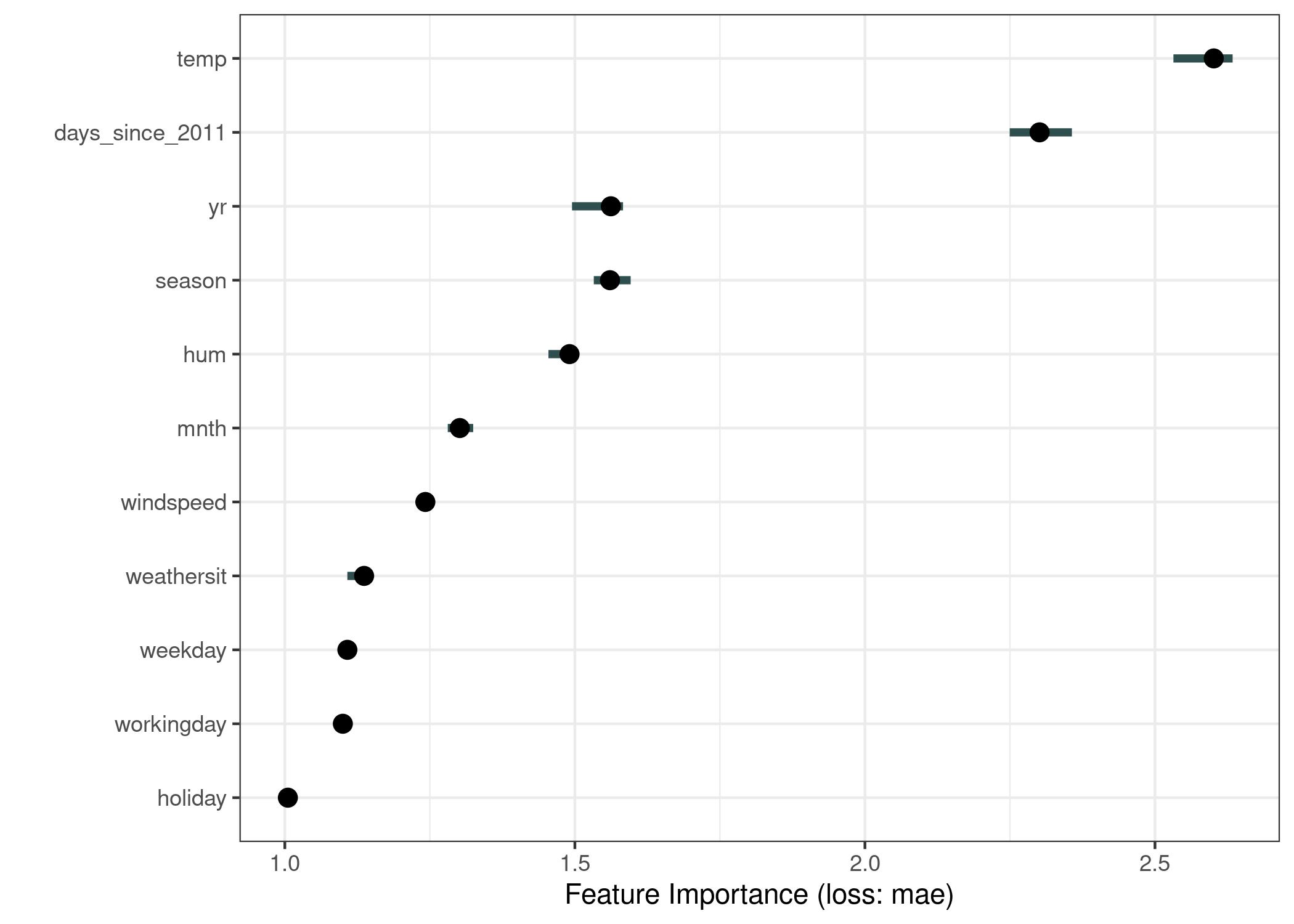
https://christophm.github.io/interpretable-ml-book/images/importance-bike-1.jpeg
7.3 Ejemplo - bicis
Se entrena un árbol de decisión a través de las predicciones de un SVM.
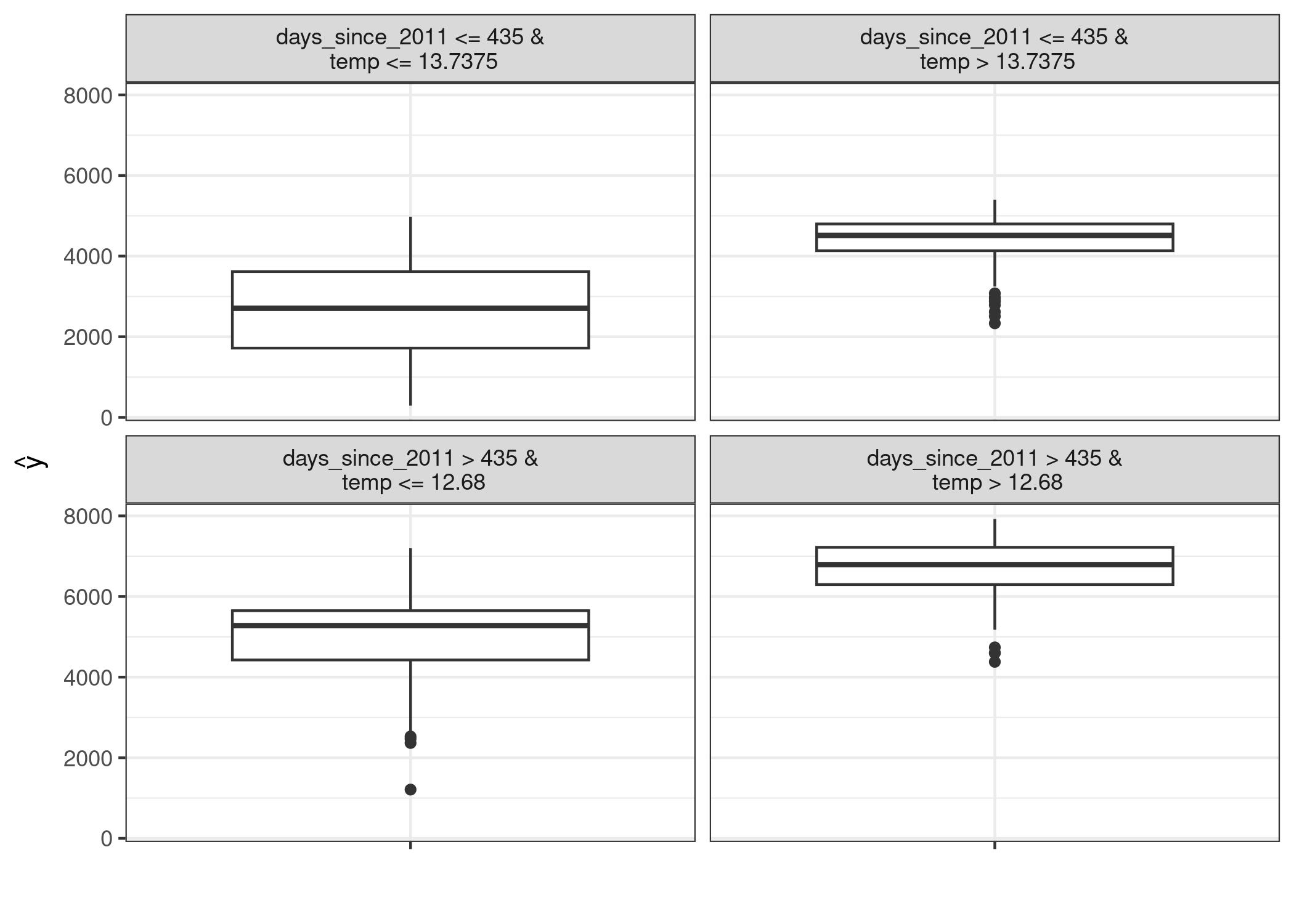
https://christophm.github.io/interpretable-ml-book/images/surrogate-bike-1.jpeg
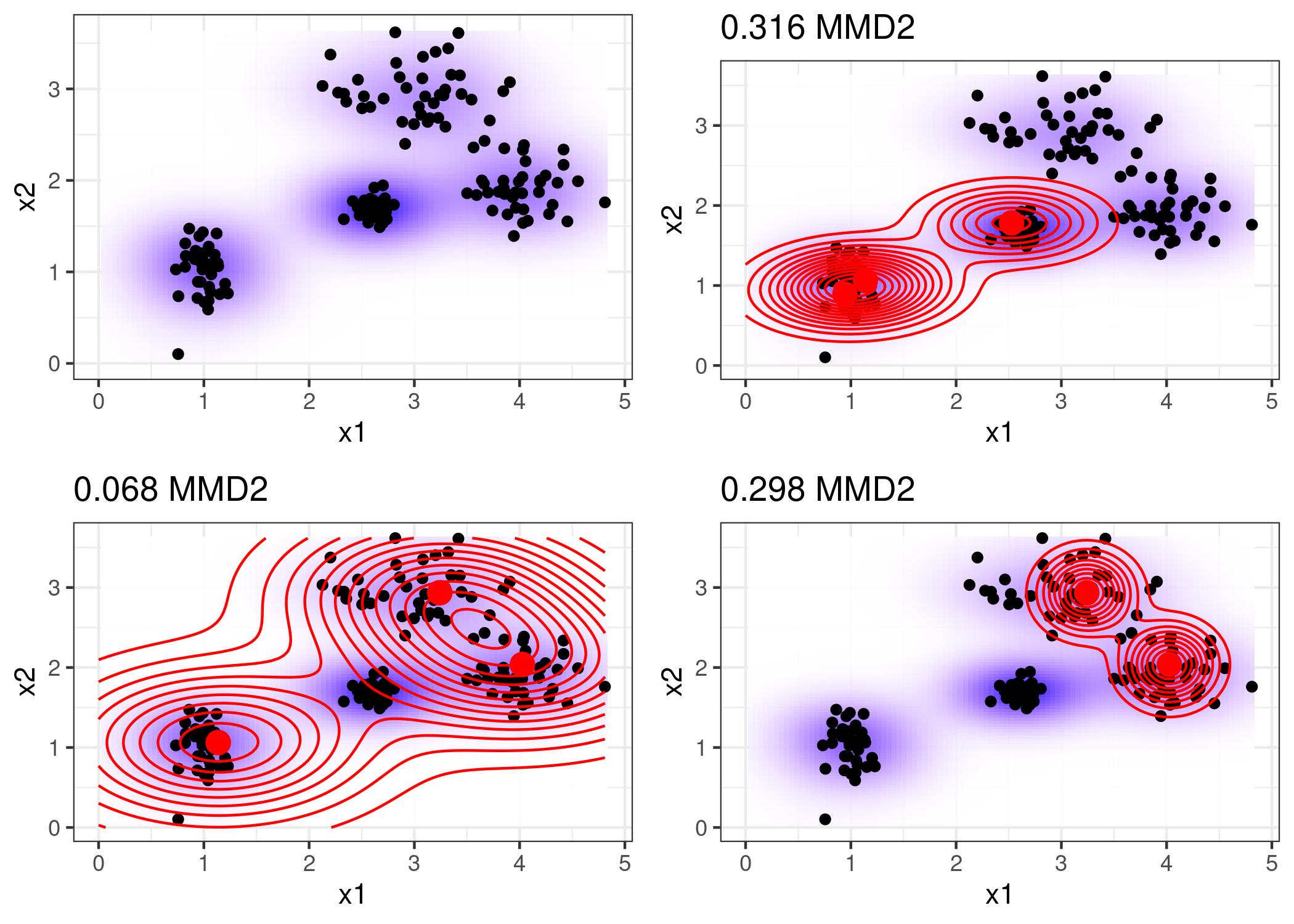
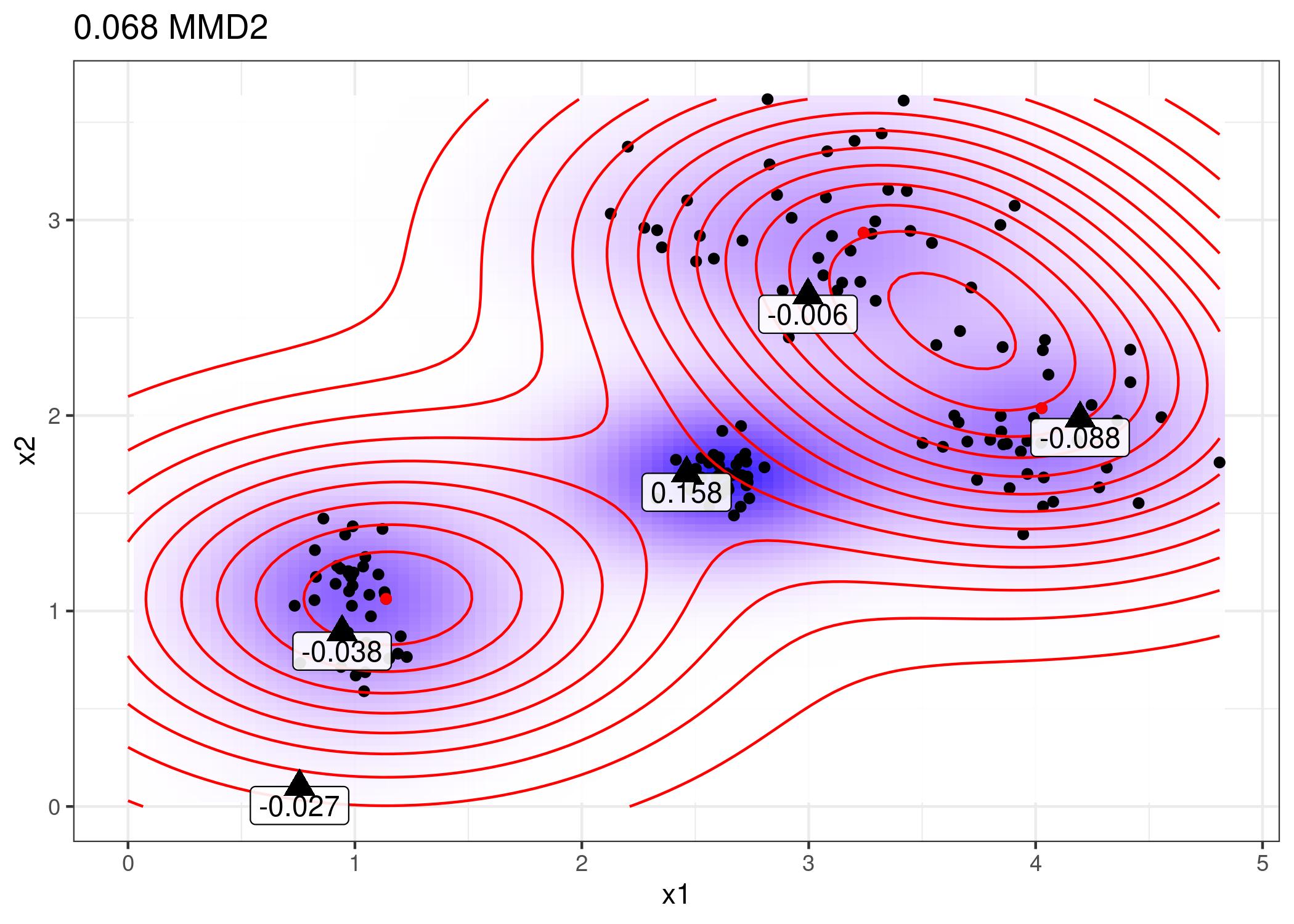
8.2 MMD-critic - Maximum Mean Discrepancy
\[MMD^2 = \frac{1}{m^2} \sum_{i,j=1}^m k(z_i, z_j) \\ - \frac{2}{mn} \sum_{i,j=1}^{m,n} k(z_i, x_j) + \frac{1}{n^2} \sum_{i,j=1}^n k(x_i, x_j)\]
- \(k\): función kernel para medir la distancia (similaridad) entre 2 puntos
- \(m\): número de prototipos
- \(n\): número de datos
- \(z\): prototipos
- \(x\): datos
El objetivo es minimizar \(MMD2\).
8.3 Función witness
Esta función mide cómo de bien se ajusta un dato \(x\) a los prototipos \(z\).
\[witness(x) = |\frac{1}{n} \sum_{i=1}^n k(x, x_i) - \frac{1}{m} \sum_{j=1}^m k(x, z_j)|\]
El objetivo es usar como críticas aquellos datos con mayor witness.
9.2 Ejemplo - Feature importance - cáncer
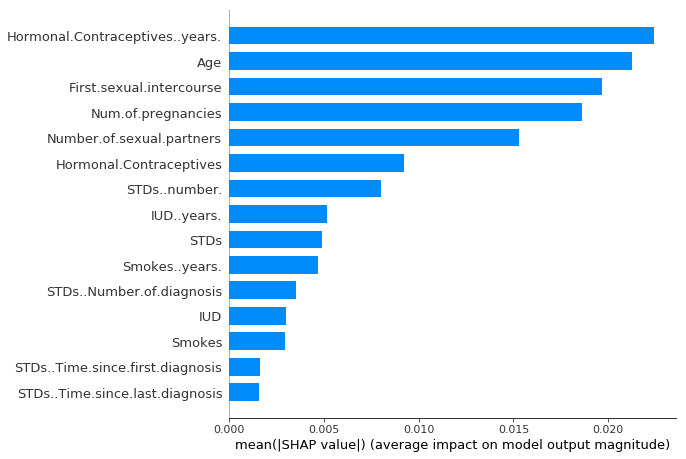
https://christophm.github.io/interpretable-ml-book/images/shap-importance.png
9.3 Ejemplo - Summary plot - cáncer
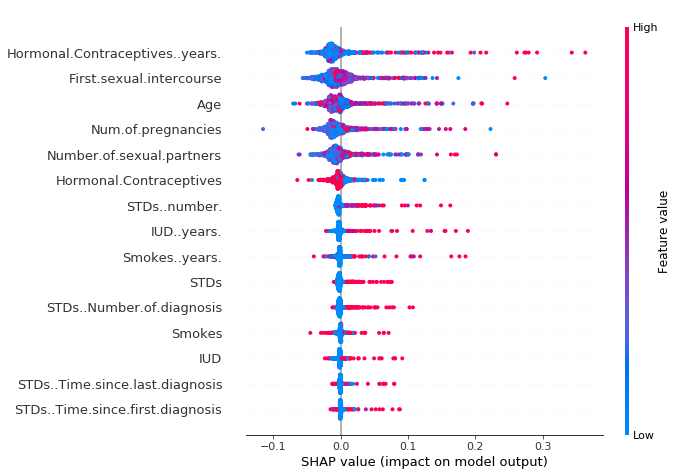
https://christophm.github.io/interpretable-ml-book/images/shap-importance-extended.png
9.4 Ejemplo - Dependence plot - cáncer
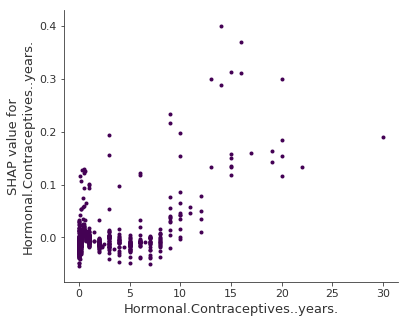
https://christophm.github.io/interpretable-ml-book/images/shap-dependence.png
9.5 Ejemplo - Feature dependence - cáncer
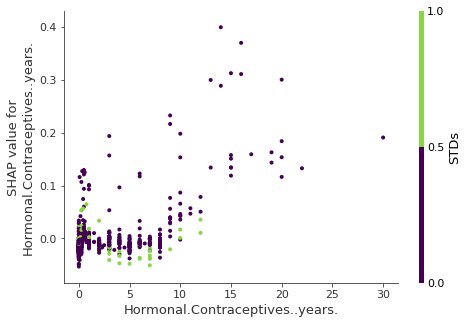
https://christophm.github.io/interpretable-ml-book/images/shap-dependence-interaction.png
9.6 Ejemplo - Force plot - cáncer