4. Local Model-Agnostic Methods
Resumen del libro de Molnar
1 ICE - Individual Conditional Expectation
1.1 Definición
Visualizar el valor predicho por el modelo para cada dato variando un único atributo \(S\) en cada individuo.
Feature Importance
For Dummies
Es dibujar por el valor predicho para cada dato cuando cambias su valor del atributo \(S\) por \(x\).
1.2 Función de expectativa condicional individual (ICE)
Siendo \(S\) el atributo a estudiar, y \(C\) el resto de atributos, la función ICE se define para cada dato como:
\[\hat{f}_{S}^{(i)}(x_S) = \hat{f}(\{x_S, x_{C}^{(i)}\})\]
1.3 Variante
1.3.1 Centered ICE
Se ancla el comienzo de la función a un valor fijo para que todas las gráficas (una por cada dato) partan del mismo punto. De esta forma se puede ver la tendencia en conjunto:
\[\hat{f}_{cent}^{(i)}=\hat{f}^{(i)}-\hat{f}(\{x^a, x_{C}^{(i)}\})\]
Siendo \(x^a\) el valor ancla.
1.4 Variante
1.4.1 (d-ICE) Derivative ICE
Calcular la derivada de cada función ICE.
\[\frac{d \hat{f}_{S}^{(i)}(x_S)}{dx_S} = g'(x_S)\]
Donde
\[\hat{f}(x) = g(x_S) + h(x_C)\]
Tip
Si el atributo es independiente con respecto al resto, la derivada debería ser la misma para todos los datos.
1.5 Ejemplo - bicis
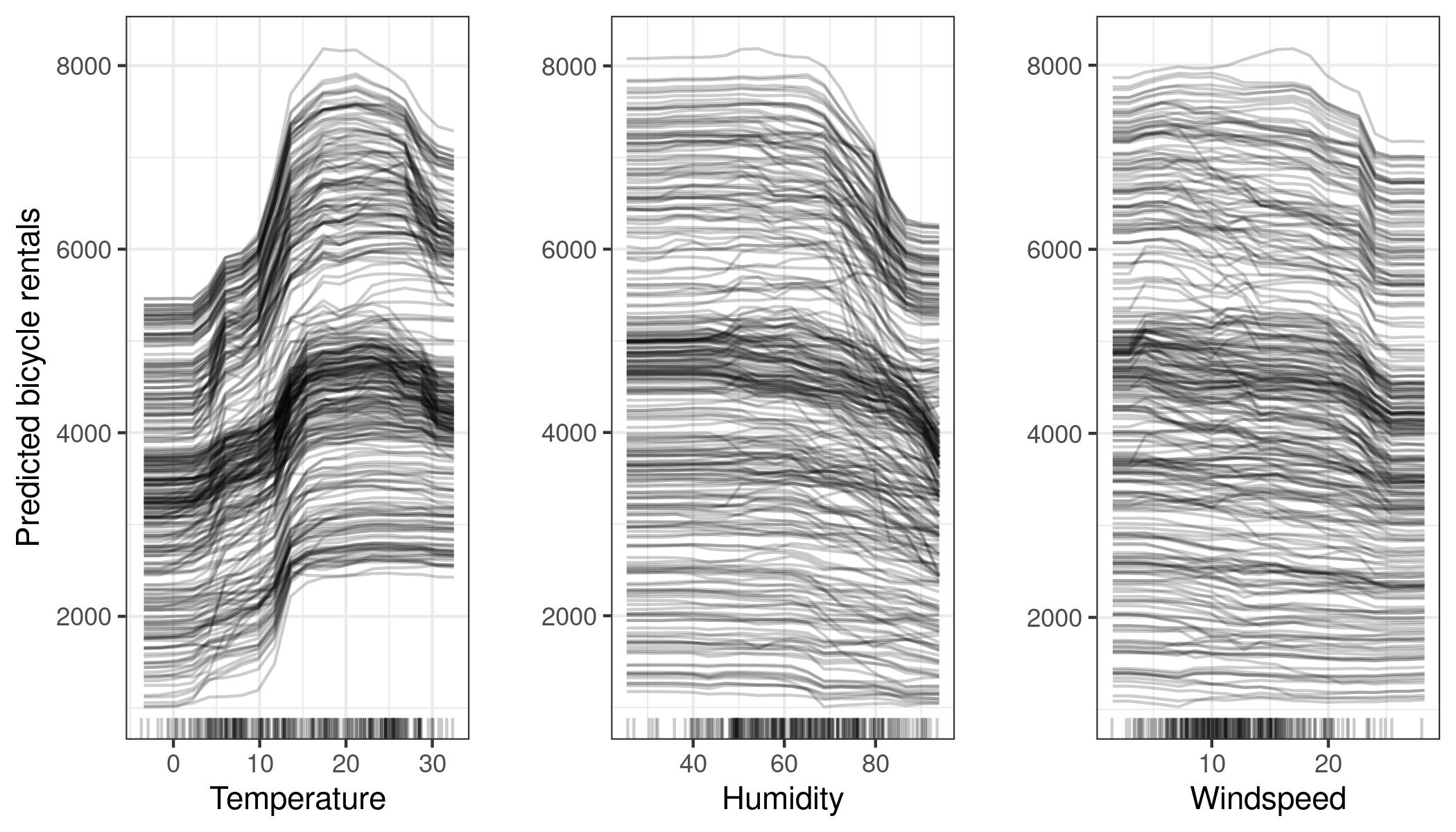
https://christophm.github.io/interpretable-ml-book/images/ice-bike-1.jpeg
1.6 Ejemplo Centered - bicis
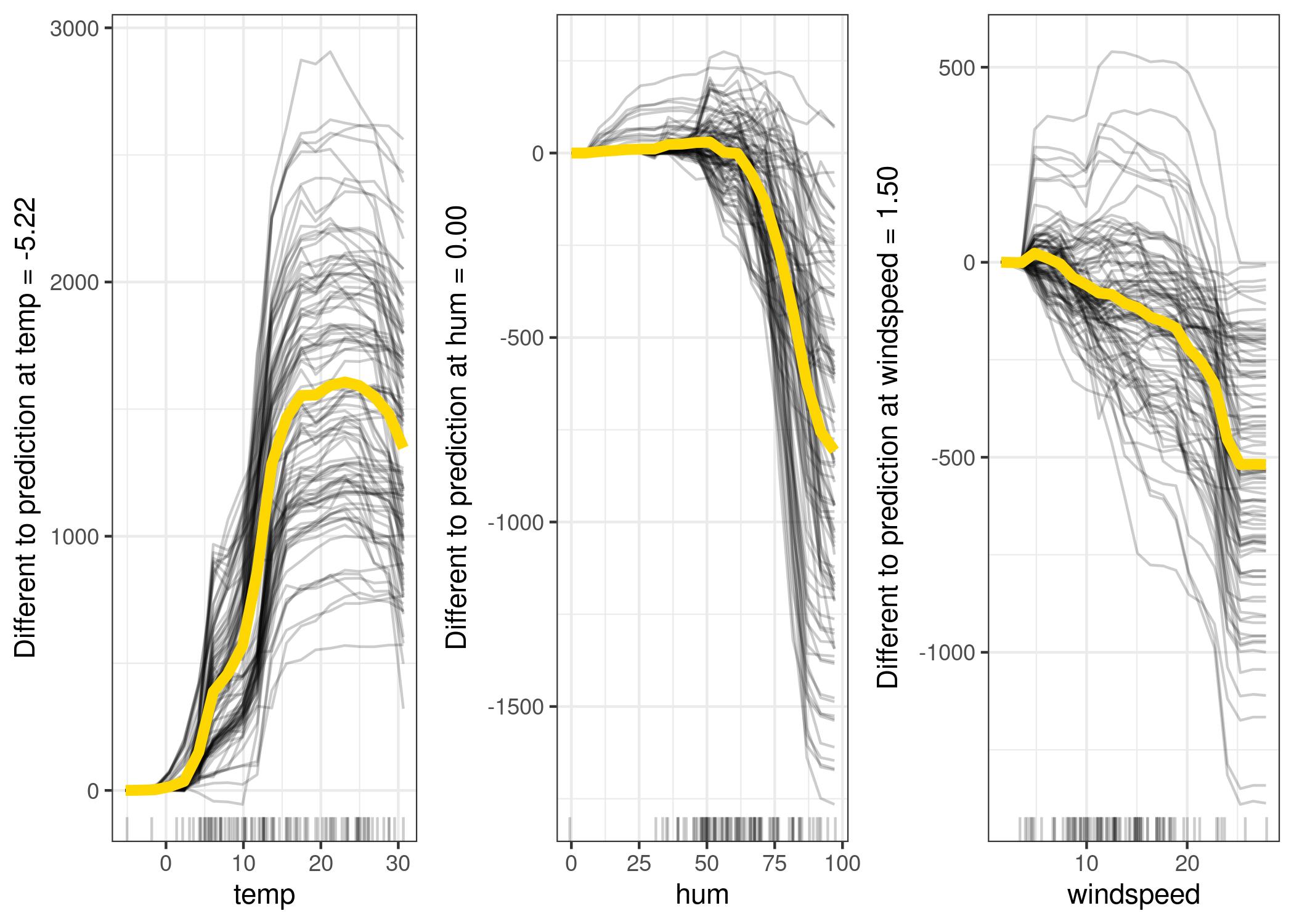
https://christophm.github.io/interpretable-ml-book/images/ice-bike-centered-1.jpeg
1.7 Pros / Cons
1.7.1 Ventajas
- Muy intuitivo
- Muestra relaciones heterogéneas entre individuos (PDP promedia)
1.7.2 Desventajas
- Solo puede mostrar 1 atributo a la vez
- Asunción de independencia: puede dar lugar a datos imposibles.
- El plot puede ser difícil de ver si existen demasiadas líneas
2 LIME - Local Interpretable Model-agnostic Explanations
2.1 Definición
El método de LIME busca entrenar un modelo subrogado inherentemente interpretable (comúnmente una regresión lineal) que solo contenga una región cercana al dato a explicar. Esto elimina la desventaja de intentar subrogar modelos excesivamente complejos de forma global, ya que una región más pequeña será más fácil de replicar.
Surrogate Models
For Dummies
Generar datos en una región cercana al individuo para subrogarla por un modelo lineal.
2.2 Matemáticamente
\(explanation(x) = argmin_{g \in G} L(f, g, \pi_x) + \Omega(g)\)
Donde:
- \(f\) es el modelo original
- \(g\) es el modelo lineal
- \(\pi_x\) define la proximidad de los datos generados para \(g\)
- \(L\) mide la diferencia entre las predicciones de \(f\) y \(g\)
- \(\Omega\) mide la complejidad del modelo
2.3 Método
- Seleccionar el dato \(x\) a explicar
- Perturbar el dataset, generar nuevos datos y obtener sus predicciones
- Sopesar los nuevos datos en función de su cercanía a \(x\)
- Entrenar un modelo lineal con los datos generados, teniendo en cuenta sus pesos
- Interpretar el modelo lineal y extrapolar la explicación a \(M\)
2.4 Ejemplo ad hoc

https://christophm.github.io/interpretable-ml-book/images/lime-fitting-1.jpeg
2.5 Ejemplo de la relevancia del kernel
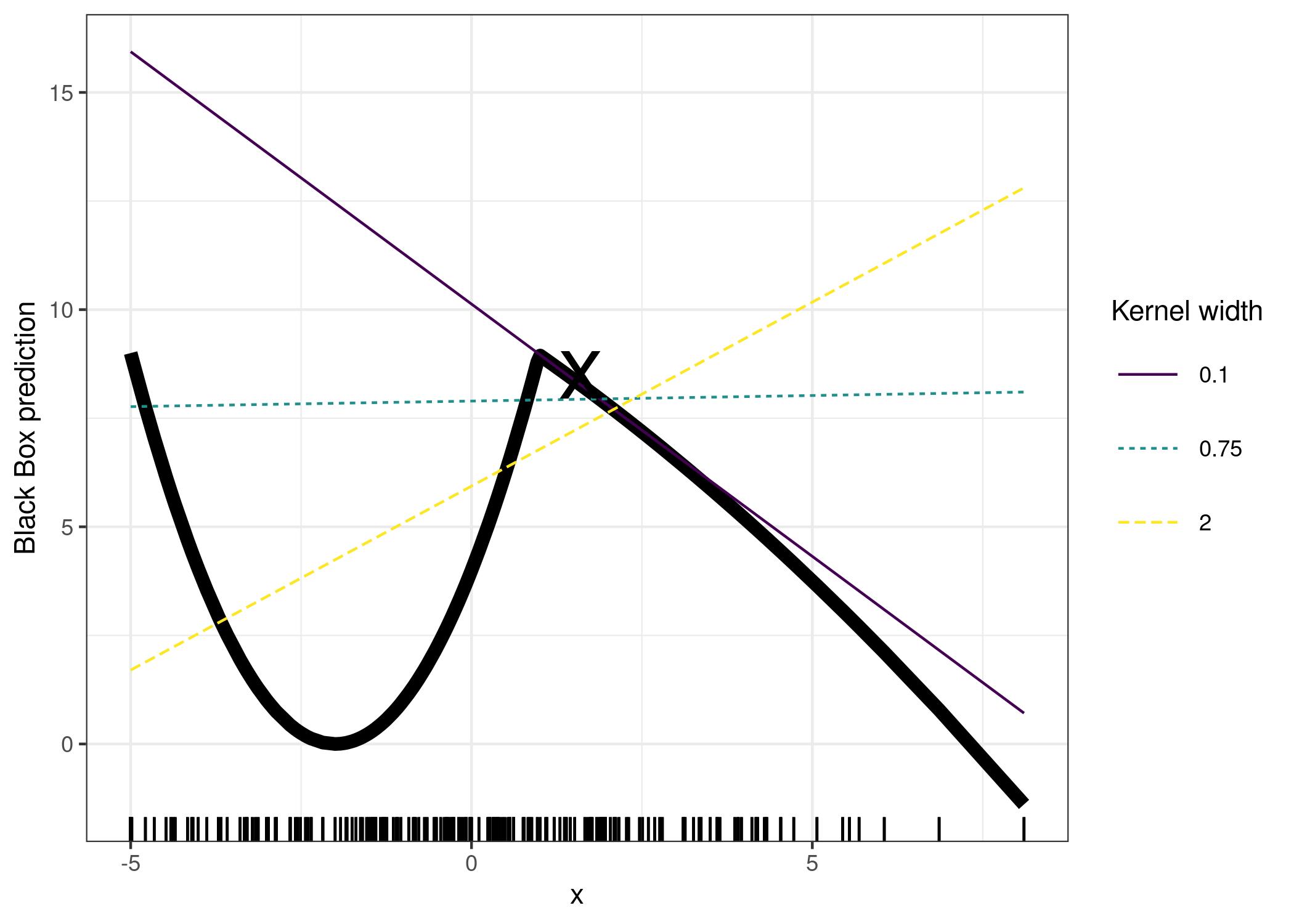
https://christophm.github.io/interpretable-ml-book/images/lime-fail-1.jpeg
2.6 Pros / Cons
2.6.1 Ventajas
- Se puede usar el modelo subrogado sustituyendo el original
- Las explicaciones son cortas y contrastables
- Funcionar para datos estructurados, imágenes y texto
- Se puede medir la fiabilidad de la explicación
2.6.2 Desventajas
- La decisión de la vecindad es subjetiva y determina el modelo generado
- Tiende a ser inestable. Un pequeño cambio en la vecindad o en el dato a estudiar tiende a dar grandes cambios en la explicación
- Por esto, se pueden manipular las explicaciones obtenidas
3 Counterfactual Explanations
3.1 Definición
Una explicación por contrafácticos intenta explicar la predicción de un dato a través de revelar cómo cambiaría la predicción si cambiase el dato en uno y otro atributo.
Se basa en conseguir modificar la predicción para el dato \(x\) en un valor \(y\) buscando un dato nuevo \(x'\). Se usan algoritmos de optimización para reducir la diferencia entre \(x\) y \(x'\) según diversas medidas.
Note
También utilizados para adversarial attacks.
Counterfactuals
For Dummies
Buscar el mínimo cambio en el dato para hacer cambiar su predicción un valor preestablecido.
3.2 Método Wachter
\[L(x, x', y', \lambda) = \lambda \cdot (\hat{f}(x') - y') + d(x, x')\]
Queremos minimizar la función de pérdida \(L\) buscando un \(x'\) que minimize la diferencia entre la predicción de \(M\) \(\hat{f}(x')\) y el valor deseado \(y'\), y que sea lo más parecido posible a \(x\): \(d(x, x')\).
3.3 Método Dandl
Queremos resolver un problema multiobjetivo (ningún objetivo más prioritario que otro) formado por los siguientes objetivos:
\(o_1\): la distancia entre \(\hat{f}(x')\) y \(y'\)
\(o_2\): la distancia entre \(x\) y \(x'\)
\(o_3\): El número de atributos que cambian
\(o_4\): \(x'\) sea parecido a algún dato existente.
3.4 Ejemplo
En un ejemplo de la denegación de un crédito:
| age | sex | job | amount | duration |
|---|---|---|---|---|
| 58 | f | unskilled | 6143 | 48 |
Estos serían los datos más cercanos:
| age | sex | job | amount | duration | o₂ | o₃ | o₄ | f̂(x′) |
|---|---|---|---|---|---|---|---|---|
| -20 | skilled | -20 | -20 | 0.108 | 2 | 0.036 | 0.501 | |
| -24 | skilled | -24 | -24 | 0.114 | 2 | 0.029 | 0.525 | |
| -22 | skilled | -22 | -22 | 0.111 | 2 | 0.033 | 0.513 | |
| -6 | skilled | -6 | -24 | 0.126 | 3 | 0.018 | 0.505 | |
| -3 | skilled | -3 | -24 | 0.120 | 3 | 0.024 | 0.515 | |
| -1 | skilled | -1 | -24 | 0.116 | 3 | 0.027 | 0.522 | |
| -3 | m | -3 | -24 | 0.195 | 3 | 0.012 | 0.501 | |
| -6 | m | -6 | -25 | 0.202 | 3 | 0.011 | 0.501 | |
| -30 | m | -30 | -24 | 0.285 | 4 | 0.005 | 0.509 | |
| -4 | m | -1254 | -24 | 0.204 | 4 | 0.002 | 0.506 |
3.5 Pros / Cons
3.5.1 Ventajas
- Explicación muy clara
- Se puede interpretar el dato objetivo, o los cambios necesarios para llegar a él
- No requiere acceder al interior del modelo o al dataset, solo a su resultado
- Sirve también para sistemas que no usan ML
- Es relativamente sencillo, y se puede usar distintos algoritmos de optimización
3.5.2 Desventajas
- Rashomon effect: para un mismo individuo pueden existir múltiples contrafácticos, que pueden ser contradictorios entre ellos
4 Scoped rules (anchors)
4.1 Definición
Intentaremos encontrar una región cercana al dato a explicar donde la predicción del modelo sea constante. Para ello buscaremos reglas que anclen la predicción a un valor constante. Una regla se considerará un ancla si cualquier dato que cumpla la regla tiene el valor de predicción esperado.
Surrogate models
For Dummies
Misma idea que LIME pero en vez de usar modelos lineales usa reglas de decisión.
4.2 Visión gráfica de LIME vs acnhors
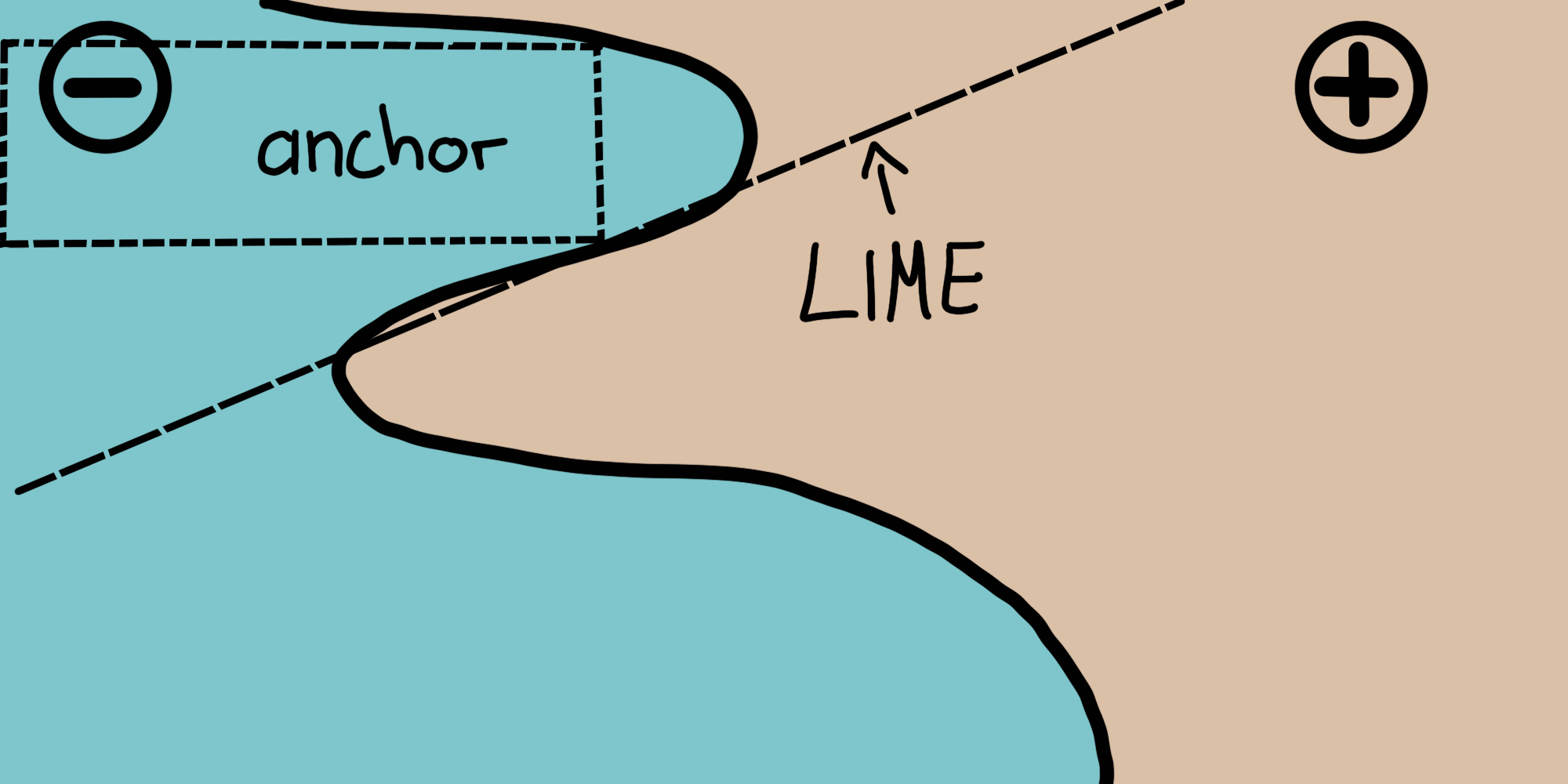
https://christophm.github.io/interpretable-ml-book/images/anchors-visualization.png
4.3 Buscar anclas
Buscar reglas o anclas que limiten el espacio es un problema computacionalmente muy costoso. Para ello se añade un \(\delta\) como la probabilidad permitida de aceptar un valor de error. \(\tau\) es el valor de precisión mínimo que se acepta.
\[P(prec(A) \geq \tau) \geq 1 - \delta\]
\[prec(A) = \mathbb{E}_{D_x(z|A)}[1_{\hat{f}(x) = \hat{f}(z)}]\]
De aquí se calcula el coverage, que es la probabilidad de que la regla se cumpla en la vecindad:
\[cov(A)=\mathbb{E}_{D_x(z)}[A(z)]\]
4.4 Ejemplo - bicis

https://christophm.github.io/interpretable-ml-book/images/anchors1-1.png
4.5 Ejemplo - cáncer
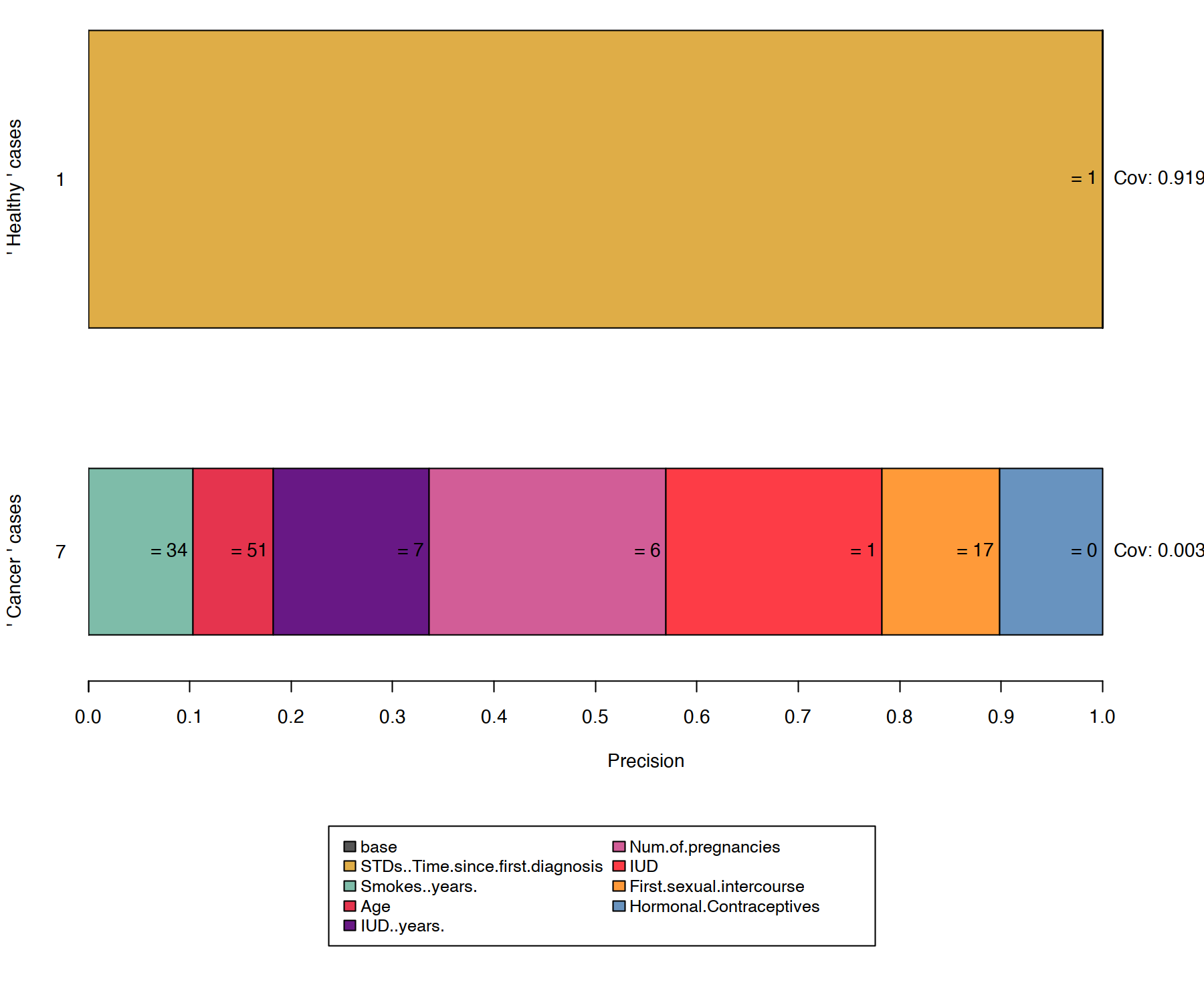
https://christophm.github.io/interpretable-ml-book/images/anchors3-1.png
4.6 Pros / Cons
4.6.1 Ventajas
- Fácil de interpretar
- Tienen la característica de coverage
- Funcionan con relaciones complejas no lineales
- Puede paralelizarse
4.6.2 Desventajas
- Altamente configurables
- Requiere discretizar los datos
- Hace muchas llamadas al modelo ML
5 Shapley Values
5.1 Definición
Si tratamos la predicción del modelo \(M\) como un juego donde cada atributo \(S_i\) es un jugador, y el valor de la predicción es la puntuación final del juego, se puede calcular la contribución de cada atributo al resultado final.
Esto se lleva a cabo mediante el cálculo de los shapley values, que son valores estudiados en la teoría de juegos cooperativos.
Feature Importance
For Dummies
Encontrar la importancia de cada atributo en la predicción del modelo a través de teoría de juegos.
5.2 Shapley Values
Para calcular el shapley value \(\phi_i\) de un atributo \(S_i\) se debe calcular previamente el valor de la predicción para todos los subconjuntos de atributos que no contengan a \(S_i\).
\[\phi_i(v) = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|!(|N|-|S|-1)!}{|N|!} [v(S \cup \{i\}) - v(S)]\]
- \(S\) es un subset de atributos
- \(N\) es el conjunto de todos los atributos
- \(v(S)\) es el valor de la predicción para el subconjunto \(S\).
Se divide el espacio de atributos en todos los subconjuntos posibles y se calcula la predicción para cada subconjunto. La aportación de un atributo se calcula a través de una media ponderada de estos valores según la fórmula de arriba.
5.3 Propiedades de los Shapley Values
- Eficiencia: la suma de los shapley values de todos los atributos es igual a la diferencia de \(\hat{f}(x)\) y la media \(\bar{\hat{f}}\).
- Simetría: si la contribución de 2 atributos es la misma para cada subconjunto, su shapley value también será el mismo.
- Dummy: si un atributo no aporta nada en ninguno de los subconjuntos, su shapley value será 0.
- Additividad: la suma de los shapley values de 2 atributos es igual a la contribución de ambos juntos.
5.4 Estimación de los Shapley Values
El número de subconjuntos de atributos crece exponencialmente con el número de atributos \(2^{S_M}\). Para evitar calcular todos los valores, calculamos aleatoriamente solo algunos subconjuntos (Montecarlo):
\[\hat{\phi_j} = \frac{1}{M} \sum_{m=1}^{M} [ \hat{f}(x_{+j}^{m}) - \hat{f(x_{-j}^{m})}]\]
Donde \(x_{+j}^{m}\) es una permutación de \(x\) con el atributo \(j\) incluido, y \(x_{-j}^{m}\) es una permutación sin él.
5.5 Algoritmo
Para un número de iteraciones \(M\) dado:
- Para cada \(m \in [1,M]\)
- Seleccionar una instancia aleatoria \(z\)
- Seleccionar una permutación aleatoria de atributos \(o\)
- ordenar la instancia a estudiar \(x\) según \(o\)
- ordenar la isntancia \(z\) según \(o\)
- Construir 2 nuevas instancias
- \(x_{+j}^{m}\): \(x = (x_{(1)}, ..., x_{(2)}, x_{(j)}, z_{(j+1)}, ..., z_{(p)})\)
- \(x_{-j}^{m}\): \(x = (x_{(1)}, ..., x_{(2)}, z_{(j)}, z_{(j+1)}, ..., z_{(p)})\)
- Calcular la contribución marginal: \(\phi_j^m = \hat{f}(x_{+j}^{m}) - \hat{f}(x_{-j}^{m})\)
- Calcular los shapley values como la media de las contribuciones marginales: \(\phi_j = \frac{1}{M} \sum_{m=1}^{M} \phi_j^m\)
5.6 Ejemplo - bicis
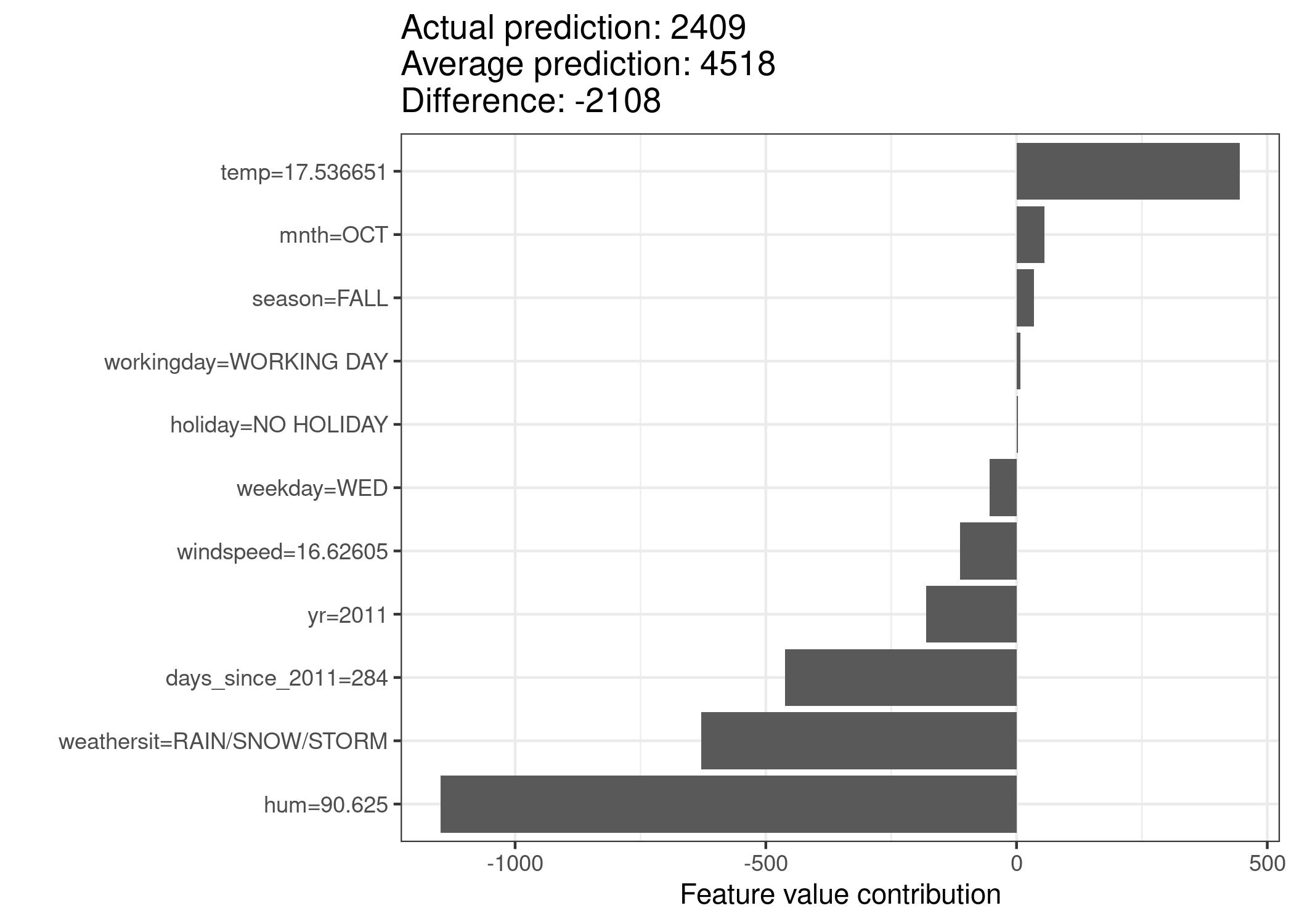
https://christophm.github.io/interpretable-ml-book/images/shapley-bike-plot-1.jpeg
5.7 Pros / Cons
5.7.1 Ventajas
- El valor de la importancia de cada atributo está justamente calculado
- Permite comparaciones contrastrables con subsets de datos
- Tiene una teoría matemática sólida detrás
5.7.2 Desventajas
- Muy costoso computacionalmente
- Es fácil de malinterpretar
- Siempre usa todas las features (aunque se pueden agrupar)
- No usa un modelo subrogado, por lo que no puede hacer predicciones
- Se necesita acceso a los datos de entrenamiento
- Al generar datos aleatorios, podemos predecir sobre datos imposibles
6 SHAP - SHapley Additive exPlanations
6.1 Definición
SHAP es un método que utiliza los shapley values para explicar el valor de la predicción de un modelo. En este caso se genera un nuevo modelo de predicción \(g\) que predice datos según los shapley values de los atributos, a través de un nuevo dataset \(D'\), donde cada dato es solo una permutación de elementos binarios, indicando si un atributo está o no presente en esa instancia.
Es similar a generar un modelo lineal que sea similar a LIME, pero donde cada peso es calculado como la contribución (shapley value) de cada atributo a la predicción.
Surrogate Model
For Dummies
Usar los shapley values para crear un modelo lineal interpretable.
6.2 Matemáticamente
\[g(z) = \phi_0 + \sum_{j=1}^{M} \phi_j z_j\]
Queremos asegurar 3 propiedades:
- Local Accuracy: \(g(x) \sim f(x)\)
- Missingness: \(x'_j = 0 \rightarrow \phi_j = 0\)
- Consistency: Si un modelo cambia la contribución marginal de un atributo, el shapley value de ese atributo debe cambiar en la misma dirección.
6.3 KernelSHAP
Una variante que nos permite estimar los shapley values de una instancia \(x\).
Creamos una función kernel \(h_x\) que permita convertir una instancia \(z'_k \in {0,1}^M\) en una instancia computable por \(\hat{f}\).
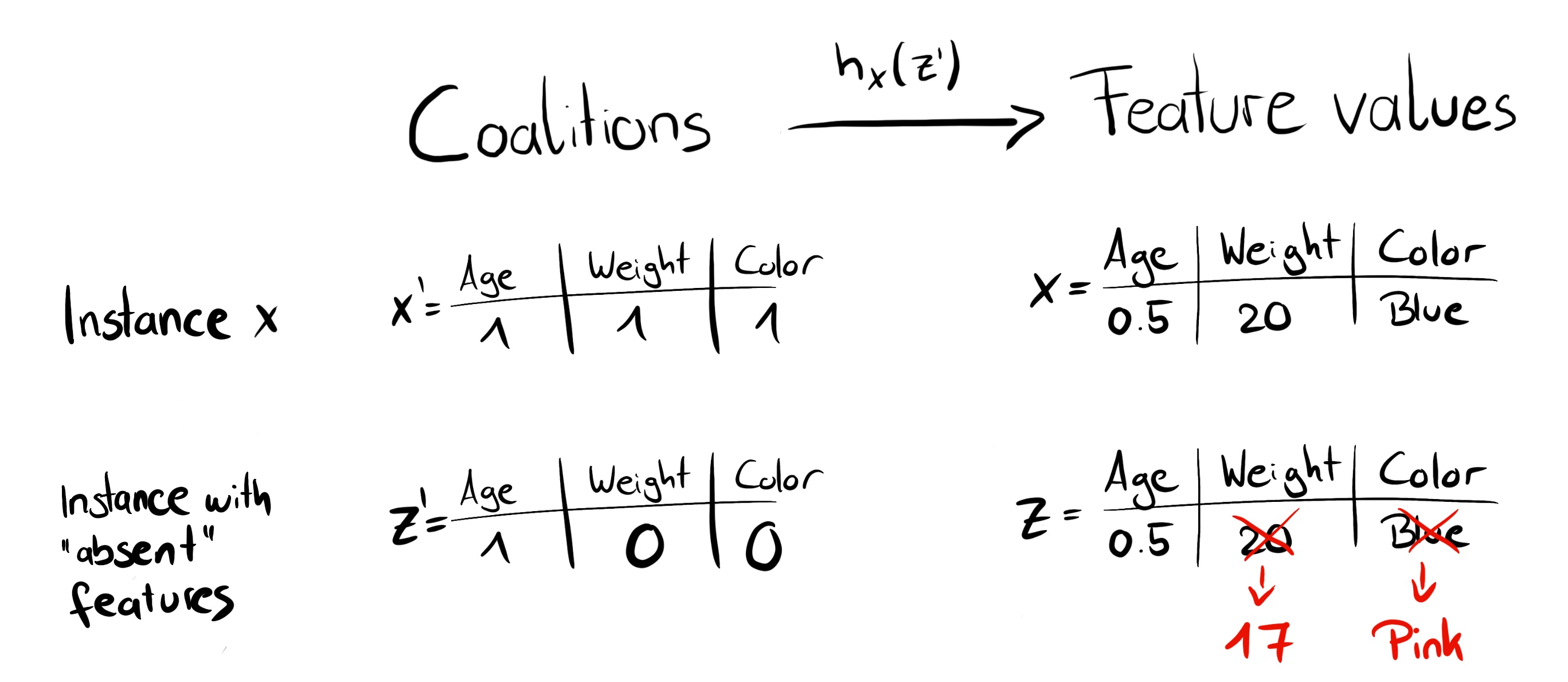
https://christophm.github.io/interpretable-ml-book/images/shap-simplified-features.jpg
6.4 Variantes
Existen distintas variantes (TreeSHAP, LinealSHAP) que permiten calcular los shapley values de formas más precisas y rápidas. Pero estas variantes no son universales, y dependen del modelo a estudiar.
6.5 SHAP para explicaciones globales
Calcular los shapley values para todos los datos del dataset nos permite obtener ciertos valores globales muy útiles con respecto al modelo:
6.5.1 SHAP Feature Importance
\[I_j = \frac{1}{n} \sum_{i=1}^{n} |\phi_j^{(i)}|\]
6.6 Ejemplo - cáncer
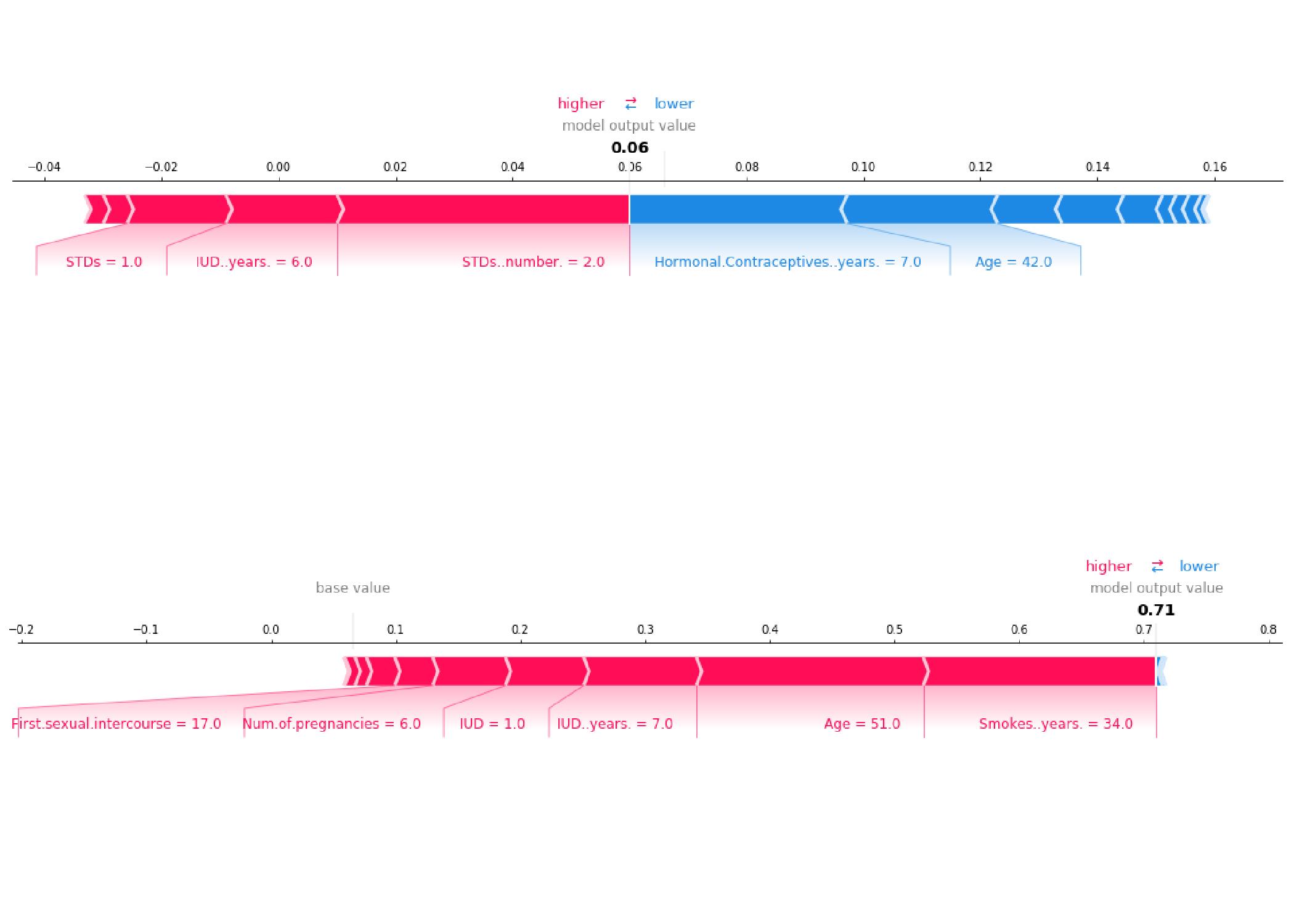
https://christophm.github.io/interpretable-ml-book/images/unnamed-chunk-39-1.jpeg
6.7 Pros / Cons
6.7.1 Ventajas
- Se basa en una teoría matemática sólida
- Conecta Shapley Values con LIME
- Diferentes implementaciones, algunas muy rápidas
- Permite explicaciones globales y locales
6.7.2 Desventajas
- Costoso computacionalmente
- Ignora las relaciones entre atributos
- Puede malinterpretarse, o manipularse para dar explicaciones incorrectas

PhD xAI